

12 Lambda-Ausdrücke und funktionale Programmierung 
»EDV-Systeme verarbeiten, womit sie gefüttert werden.
Kommt Mist rein, kommt Mist raus.«
– André Kostolany (1906–1999)
An der Entwicklung von Maschinensprache (bzw. Assembler) hin zur Hochsprache ist eine interessante Geschichte der Parametrisierung abzulesen. Schon die ersten Hochsprachen erlaubten eine Parametrisierung von Funktionen mit unterschiedlichen Argumenten. Java wurde im Jahr 1996 »geboren«, also mehrere Jahrzehnte nach den ersten Hochsprachen, und bot von Anfang an parametrisierte Unterprogramme an. Relativ spät folgten dann die Generics; die Parametrisierung des Typs wurde erst 2004 mit der Version 5 realisiert. Bis dahin konnte die Datenstruktur Liste zum Beispiel Zeichenketten ebenso enthalten wie Pantoffeltierchen-Objekte. Funktionale Programmierung ermöglichte nun eine Parametrisierung des Verhaltens – eine Sortiermethode arbeitet immer gleich, aber ihr Verhalten bei den Vergleichen wird angepasst. Das ist eine ganz andere Qualität, als unterschiedliche Werte zu übergeben. Mit Lambda-Ausdrücken ist die Parametrisierung des Verhaltens ganz einfach.
12.1 Funktionale Schnittstellen und Lambda-Ausdrücke
Schnittstellen spielen in Java eine wichitge Rolle, weil sie eine API vorschreiben und ein Bindeglied zwischen der Implementierung und dem Aufrufer sind. Über ein Jahrzehnt boten nur Klassen einen Weg, um Schnittstellen zu implementieren, doch ab Java 8 hat sich das für einige Schnittstellentypen verändert.
12.1.1 Klassen implementieren Schnittstellen
Klassen kommen in verschiedenen Ausprägungen vor – schauen wir uns zwei Wege an.
Geschachtelte Klassen als Code-Transporter
Angenommen, wir sollen Strings so sortieren, dass Weißraum vorne und hinten bei den Vergleichen ignoriert wird, also " Newton " gleich "Newton" ist. Bei Vorgaben dieser Art muss einem Sortieralgorithmus ein Comparator als ein Stückchen Code übergeben werden, damit er die korrekte Reihenfolge herstellen kann. Praktisch sieht das so aus:
Listing 12.1 src/main/java/com/tutego/insel/lambda/TrimCompare.java, main()
public static void main( String[] args ) {
class TrimComparator implements Comparator<String> {
@Override public int compare( String s1, String s2 ) {
return s1.trim().compareTo( s2.trim() );
}
}
String[] words = { "M", "\nSkyfall", " Q", "\t\tAdele\t" };
Arrays.sort( words, new TrimComparator() );
System.out.println( Arrays.toString( words ) );
}
Die Ausgabe ist:
[ Adele , M, Q,
Skyfall]
Der TrimComparator enthält in der compare(…)-Methode den Programmcode für die Vergleichslogik. Ein Exemplar vom TrimComparator wird aufgebaut und Arrays.sort(…) übergeben. Das geht mit weniger Code!
Innere anonyme Klassen als Code-Transporter
Klassen enthalten Programmcode, und Exemplare der Klassen werden an Methoden wie sort(…) übergeben, damit der Programmcode dort hinkommt, wo er gebraucht wird. Doch elegant ist das nicht. Für die Beschreibung des Programmcodes ist extra eine eigene Klasse erforderlich. Das ist viel Schreibarbeit, und über eine innere anonyme Klasse lässt sich der Programmcode schon ein wenig verkürzen:
String[] words = { "M", "\nSkyfall", " Q", "\t\tAdele\t" };
Arrays.sort( words, new Comparator<String>() {
@Override public int compare( String s1, String s2 ) {
return s1.trim().compareTo( s2.trim() );
} } );
System.out.println( Arrays.toString( words ) );
Allerdings ist das immer noch aufwendig: Wir müssen eine Methode überschreiben und dann ein Objekt aufbauen. Für Programmautoren ist das lästig, und die JVM hat es mit vielen überflüssigen Klassendeklarationen zu tun. Die Frage ist: Wenn der Compiler weiß, dass bei sort(…) ein Comparator nötig ist, und wenn ein Comparator sowieso nur eine Methode hat, müssen dann Comparator und compare(…) überhaupt genannt werden?
12.1.2 Lambda-Ausdrücke implementieren Schnittstellen
Mit Lambda-Ausdrücken lässt sich Programmcode leichter an eine Methode übergeben, denn es gibt eine kompakte Syntax für die Implementierung von Schnittstellen mit einer Operation. Für unser Beispiel sieht das so aus:
String[] words = { "M", "\nSkyfall", " Q", "\t\tAdele\t" };
Comparator<String> c = (String s1, String s2) ->
{ return s1.trim().compareTo( s2.trim() ); }
Arrays.sort( words, c );
System.out.println( Arrays.toString( words ) );
Der fett gesetzte Ausdruck nennt sich Lambda-Ausdruck. Er ist eine kompakte Art und Weise, Schnittstellen mit genau einer Methode zu implementieren: Die Schnittstelle Comparator hat genau eine Operation compare(…).
Optisch sind sich ein Lambda-Ausdruck und eine Methodendeklaration ähnlich; was wegfällt, sind Modifizierer, der Rückgabetyp, der Methodenname und (mögliche) throws-Klauseln.
Methodendeklaration | Lambda-Ausdruck |
|---|---|
public int compare |
|
Tabelle 12.1 Vergleich der Methodendeklaration einer Schnittstelle mit dem Lambda-Ausdruck
Wenn wir uns den Lambda-Ausdruck als Implementierung dieser Schnittstelle anschauen, dann lässt sich dort nichts von Comparator oder compare(…) ablesen – ein Lambda-Ausdruck repräsentiert mehr oder weniger nur den Java-Code und lässt das weg, was der Compiler aus dem Kontext herleiten kann.
Den Lambda-Ausdruck haben wir explizit in einer Variablen gespeichert, doch wir hätten ihn auch direkt als Argument von Arrays.sort(…) einsetzen können:
Arrays.sort( words,
(String s1, String s2) -> { return s1.trim().compareTo(s2.trim()); } );
Das ist natürlich schön kompakt und viel kürzer als mit anoymen Klassen.
Allgemeine Syntax für Lambda-Ausdrücke
Alle Lambda-Ausdrücke lassen sich in einer Syntax formulieren, die die folgende allgemeine Form hat:
( LambdaParameter ) -> { Anweisungen }
Lambda-Parameter sind sozusagen die Eingabewerte für die Anweisungen. Die Parameterliste wird so deklariert, wie von Methoden oder Konstruktoren bekannt, allerdings gibt es keine Varargs. Es gibt syntaktische Abkürzungen, wie wir später sehen werden, doch vorerst bleiben wir bei dieser Schreibweise.
[zB] Beispiel
Die Parameterliste kann leer sein und die Rückgabe void – wie im Beispiel der Schnittstelle Runnable, die eine Methode void run() hat. Wir können schreiben: Runnable run = () -> {};.
[»] Geschichte
Der Java-Begriff Lambda-Ausdruck geht auf das Lambda-Kalkül (in der englischen Literatur Lambda calculus genannt, auch geschrieben als λ-calculus) aus den 1930er-Jahren zurück und ist eine formale Sprache zur Untersuchung von Funktionen.
12.1.3 Funktionale Schnittstellen
Nicht zu jeder Schnittstelle gibt es eine Abkürzung über einen Lambda-Ausdruck, und es gibt eine zentrale Bedingung, wann ein Lambda-Ausdruck verwendet werden kann.
[»] Definition
Schnittstellen, die nur eine Operation (abstrakte Methode) besitzen, heißen funktionale Schnittstellen. Ein Funktionsdeskriptor beschreibt diese Methode. Eine abstrakte Klasse mit genau einer abstrakten Methode zählt nicht als funktionale Schnittstelle.
Lambda-Ausdrücke und funktionale Schnittstellen haben eine ganz besondere Beziehung, denn ein Lambda-Ausdruck ist ein Exemplar einer solchen funktionalen Schnittstelle. Natürlich müssen Typen und Ausnahmen passen. Dass funktionale Schnittstellen genau eine abstrakte Methode vorschreiben, ist eine naheliegende Einschränkung, denn gäbe es mehrere, müsste ein Lambda-Ausdruck ja auch mehrere Implementierungen anbieten oder irgendwie eine Methode bevorzugen und andere ausblenden.
Wenn wir ein Objekt vom Typ einer funktionalen Schnittstelle aufbauen möchten, können wir folglich zwei Wege einschlagen: Wir können die traditionelle Konstruktion über die Bildung von Klassen wählen, die funktionale Schnittstellen implementieren, und dann mit new ein Exemplar bilden, oder wir können mit kompakten Lambda-Ausdrücken arbeiten. Moderne IDEs zeigen uns an, wenn kompakte Lambda-Ausdrücke zum Beispiel statt innerer anonymer Klassen genutzt werden können, und bieten uns mögliche Refactorings an. Lambda-Ausdrücke machen den Code kompakter und nach kurzer Eingewöhnung auch lesbarer.
[»] Hinweis
Funktionale Schnittstellen müssen auf genau eine zu implementierende Methode hinauslaufen, auch wenn aus Oberschnittstellen mehrere Operationen vorgeschrieben werden, die sich aber durch den Einsatz von Generics auf eine Operation verdichten:
interface I<S, T extends CharSequence> {
void len( S text );
void len( T text );
}
interface FI extends I<String, String> { }
FI ist unsere funktionale Schnittstelle mit einer eindeutigen Operation len(String). Statische und Default-Methoden stören in funktionalen Schnittstellen nicht.
Viele funktionale Schnittstellen in der Java-Standardbibliothek
Java bringt viele Schnittstellen mit, die als funktionale Schnittstellen gekennzeichnet sind. Eine kleine Auswahl:
interface Runnable { void run(); }
interface Supplier<T> { T get(); }
interface Consumer<T> { void accept(T t); }
interface Comparator<T> { int compare(T o1, T o2); }
interface ActionListener { void actionPerformed(ActionEvent e); }
Viele davon befinden sich im Paket java.util.function, das in Java 8 eingeführt wurde.
Ob die Schnittstelle noch andere statische Methoden oder Default-Methoden hat – also Schnittstellenmethoden mit vorgegebener Implementierung –, ist egal, wichtig ist nur, dass sie genau eine zu implementierende Operation deklariert.
12.1.4 Der Typ eines Lambda-Ausdrucks ergibt sich durch den Zieltyp
In Java hat jeder Ausdruck einen Typ. Die Ausdrücke 1 und 1*2 haben einen Typ (nämlich int), genauso wie "A" + "B" (Typ String) oder String.CASE_INSENSITIVE_ORDER (Typ Comparator<String>). Lambda-Ausdrücke haben auch immer einen Typ, denn ein Lambda-Ausdruck ist wie ein Exemplar einer funktionalen Schnittstelle. Damit steht auch der Typ fest. Allerdings verhält es sich im Vergleich zu Ausdrücken wie 1*2 bei Lambda-Ausdrücken etwas anders, denn der Typ von Lambda-Ausdrücken ergibt sich ausschließlich aus dem Kontext. Erinnern wir uns an den Aufruf von sort(…):
Arrays.sort( words, (String s1, String s2) -> { return ... } );
Dort steht nichts vom Typ Comparator, sondern der Compiler erkennt aus dem Typ des zweiten Parameters von sort(…), der ja Comparator ist, ob der Lambda-Ausdruck auf die Methode des Comparators passt oder nicht.
Der Typ eines Lambda-Ausdrucks ist folglich abhängig davon, welche funktionale Schnittstelle er im jeweiligen Kontext gerade realisiert. Der Compiler kann ohne Kenntnis des Zieltyps (engl. target type) keinen Lambda-Ausdruck aufbauen (siehe Abbildung 12.1).
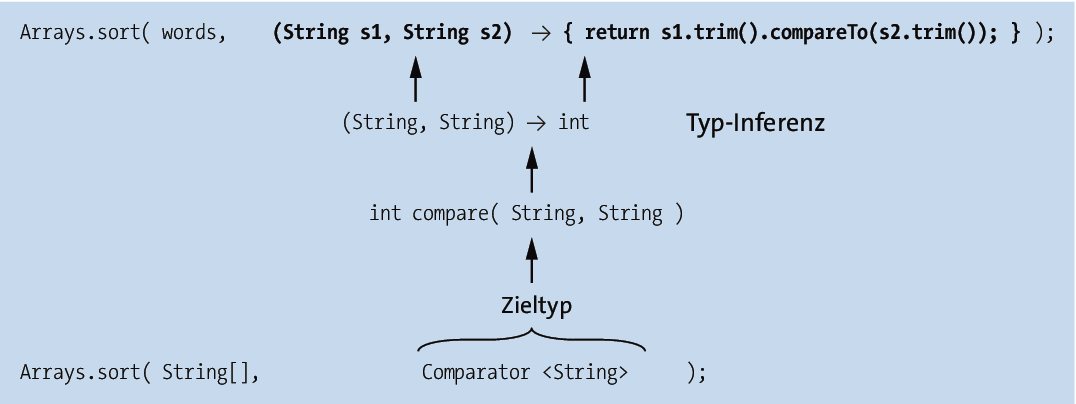
Abbildung 12.1 Typ-Inferenz des Compilers
[zB] Beispiel
Callable und Supplier sind funktionale Schnittstellen mit Methoden, die keine Parameterlisten deklarieren und eine Referenz zurückgeben; der Code für den Lambda-Ausdruck sieht gleich aus:
java.util.concurrent.Callable<String> c = () -> { return "Rückgabe"; };
java.util.function.Supplier<String> s = () -> { return "Rückgabe"; };
Wer bestimmt den Zieltyp?
Gerade weil an dem Lambda-Ausdruck der Typ nicht abzulesen ist, kann er nur dort verwendet werden, wo ausreichend Typinformationen vorhanden sind. Das sind unter anderem die folgenden Stellen:
Beispiel | |
|---|---|
Variablendeklarationen | Runnable run = () -> { }; |
Zuweisungen an deklarierte Variablen | Runnable run; run = () -> { }; |
Argumente an Methoden oder Konstruktoren | Arrays.sort( list, (s, t) -> { return 0; } ); |
Methodenrückgaben | Runnable boring() { return () -> { }; } |
Array-Initialisierungen | Runnable[] runnables = { () -> { }, () -> { } }; |
Typumwandlung | Object o = (Runnable) () -> { }; |
Tabelle 12.2 Kontextgebende Stellen für Lambda-Ausdrücke
Möglich ist der Einsatz also immer, wenn genug Kontextinformation vorhanden ist. Das gilt auch für den Bedingungsoperator – er kann je nach Bedingung einen unterschiedlichen Lambda-Ausdruck liefern. Beispiel:
Supplier<Double> randomNegOrPos = Math.random() > 0.5 ? () -> { return Math.random(); } : () -> { return -Math.random(); };
[»] Hinweis
Eine lokale Variablendeklaration mit var funktioniert mit Lambda-Ausdrücken nicht: Der Lambda-Ausdruck braucht die linke Seite und var den Typ auf der rechten.
var o = () -> {}; //Lambda expression needs an explicit target-type
Parametertypen
In der Praxis ist der häufigste Fall, dass die Parametertypen von Methoden den Zieltyp vorgeben. Der Einsatz von Lambda-Ausdrücken ändert ein wenig die Sichtweise auf überladene Methoden. Unser Beispiel mit () -> { return "Rückgabe"; } macht das deutlich, denn es »passt« auf den Zieltyp Callable<String> genauso wie auf Supplier<String>. Nehmen wir zwei überladene Methoden run(…) an:
class OverloadedFuntionalInterfaceMethods {
static <V> void run( Callable<V> callable ) { }
static <V> void run( Supplier<V> callable ) { }
}
Spielen wir den Aufruf der Methoden einmal durch:
Callable<String> c = () -> { return "Rückgabe"; };
Supplier<String> s = () -> { return "Rückgabe"; };
run( c );
run( s );
// run( () -> { return "Rückgabe"; } ); //
run( (Callable<String>) () -> { return "Rückgabe"; } );
Rufen wir run(c) bzw. run(s) auf, ist das kein Problem, denn c und s sind klar typisiert. Aber run(…) mit dem Lambda-Ausdruck aufzurufen funktioniert nicht, denn der Zieltyp (entweder Callable oder Supplier) ist mehrdeutig; der (Eclipse-)Compiler meldet: »The method run(Callable<Object>) is ambiguous for the type T«. Hier sorgt eine explizite Typumwandlung für Abhilfe.
[+] Tipp zum API-Design
Aus Sicht eines API-Designers sind überladene Methoden natürlich schön; aus Sicht des Nutzers sind Typumwandlungen aber nicht schön. Um explizite Typumwandlungen zu vermeiden, sollte auf überladene Methoden verzichtet werden, wenn diese den Parametertyp einer funktionalen Schnittstelle aufweisen. Stattdessen lassen sich die Methoden unterschiedlich benennen (was bei Konstruktoren natürlich nicht funktioniert). Wird in unserem Fall die Methode runCallable(…) und runSupplier(…) genannt, ist keine Typumwandlung mehr nötig, und der Compiler kann den Typ herleiten.
Rückgabetypen
Typ-Inferenz spielt bei Lambda-Ausdrücken eine große Rolle – das gilt insbesondere für die Rückgabetypen, die überhaupt nicht in der Deklaration auftauchen und für die es gar keine Syntax gibt; der Compiler »inferrt« sie. In unserem Beispiel
Comparator<String> c =
(String s1, String s2) -> { return s1.trim().compareTo( s2.trim() ); };
ist String als Parametertyp der Comparator-Methode ausdrücklich gegeben; der Rückgabetyp int, den der Ausdruck s1.trim().compareTo( s2.trim()) liefert, taucht dagegen nicht auf.
Mitunter muss dem Compiler etwas geholfen werden: Nehmen wir die funktionale Schnittstelle Supplier<T>, die eine Methode T get() deklariert, für ein Beispiel. Die Zuweisung
ist nicht korrekt und führt zum Compilerfehler »incompatible types: bad return type in lambda expression«. 2 ist ein Literal vom Typ int, und der Compiler kann es nicht an Long anpassen. Wir müssen
Supplier<Long> two = () -> { return 2L };
schreiben oder:
Supplier<Long> two = () -> { return (long) 2 };
Bei Lambda-Ausdrücken gelten keine wirklich neuen Regeln im Vergleich zu Methodenrückgaben, denn auch eine Methodendeklaration wie
Long two() { return 2; } //
wird vom Compiler bemängelt. Doch weil Wrapper-Typen durch die Generics bei funktionalen Schnittstellen viel häufiger sind, treten diese Besonderheiten öfter auf als bei Methodendeklarationen.
Sind Lambda-Ausdrücke Objekte?
Ein Lambda-Ausdruck ist ein Exemplar einer funktionalen Schnittstelle und tritt als Objekt auf. Bei Objekten besteht normalerweise zu java.lang.Object immer eine natürliche Ist-eine-Art-von-Beziehung. Fehlt aber der Kontext, ist selbst die Ist-eine-Art-von-Beziehung zu java.lang.Object gestört und Folgendes nicht korrekt:
Object o = () -> {}; // CompilerfehlerDer Compilerfehler ist: »incompatible types: the target type must be a functional interface«. Nur eine explizite Typumwandlung kann den Fehler korrigieren und dem Compiler den Zieltyp vorgeben:
Object r = (Runnable) () -> {};Lambda-Ausdrücke haben keinen eigenen Typ an sich, und für das Typsystem von Java ändert sich im Prinzip nichts. Möglicherweise ändert sich das in späteren Java-Versionen.
[»] Hinweis
Dass Lambda-Ausdrücke Objekte sind, ist eine Eigenschaft, die nicht überstrapaziert werden sollte. So sind die üblichen Object-Methoden equals(Object), hashCode(), getClass(), toString() und die zur Thread-Kontrolle ohne besondere Bedeutung. Es sollte auch nie ein Szenario geben, in dem Lambda-Ausdrücke mit == verglichen werden müssen, denn das Ergebnis ist laut Spezifikation undefiniert. Echte Objekte haben eine Identität, einen Identity-Hashcode, lassen sich vergleichen und mit instanceof testen und können mit einem synchronisierten Block abgesichert werden – all dies gilt für Lambda-Ausdrücke nicht. Im Grunde charakterisiert der Begriff »Lambda-Ausdruck« schon sehr gut, was wir nie vergessen sollten: Es handelt sich um einen Ausdruck, also etwas, was ausgewertet wird und ein Ergebnis produziert.
12.1.5 Annotation @FunctionalInterface
Jede Schnittstelle mit genau einer abstrakten Methode eignet sich als funktionale Schnittstelle und damit für einen Lambda-Ausdruck. Jedoch soll nicht jede Schnittstelle in der API, die im Moment nur eine abstrakte Methode deklariert, auch für Lambda-Ausdrücke verwendet werden. So kann zum Beispiel eine Weiterentwicklung der Schnittstelle mit mehreren (abstrakten) Methoden geplant sein, aber zurzeit ist nur eine abstrakte Methode vorhanden. Der Compiler kann nicht wissen, ob sich eine Schnittstelle vielleicht weiterentwickelt.
Um kenntlich zu machen, dass ein interface als funktionale Schnittstelle gedacht ist, existiert der Annotationstyp FunctionalInterface im java.lang-Paket. Diese Annotation markiert, dass es bei genau einer abstrakten Methode und damit bei einer funktionalen Schnittstelle bleiben soll.
[zB] Beispiel
Eine eigene funktionale Schnittstelle sollte immer als FunctionalInterface markiert werden:
@FunctionalInterface
public interface Buyable {
double price();
}
Der Compiler prüft, ob die Schnittstelle mit einer solchen Annotation tatsächlich nur exakt eine abstrakte Methode enthält, und löst einen Fehler aus, wenn dem nicht so ist. Aus Kompatibilitätsgründen erzwingt der Compiler diese Annotation bei funktionalen Schnittstellen allerdings nicht. Das ermöglicht es, geschachtelte Klassen, die herkömmliche Schnittstellen mit einer Methode implementieren, einfach in Lambda-Ausdrücke umzuschreiben. Die Annotation ist also keine Voraussetzung für die Nutzung der Schnittstelle in einem Lambda-Ausdruck und dient bisher nur der Dokumentation. In der Java SE sind aber alle zentralen funktionalen Schnittstellen so ausgezeichnet.
[+] Tipp
Was mit @FunctionalInterface ausgezeichnet ist, bekommt in der Javadoc einen Extrasatz: »Functional Interface: This is a functional interface and can therefore be used as the assignment target for a lambda expression or method reference.« Das macht funktionale Schnittstellen noch besser sichtbar.
[»] Hinweis
Der Annotationstyp FunctionalInterface ist auch zur Laufzeit sichtbar, was heißt, dass auch Programme über Reflection testen können, ob eine Schnittstelle annotiert ist.[ 218 ](Der Annotationstyp ist selbst mit @Documented @Retention(value=RUNTIME) @Target(value=TYPE) annotiert. )
12.1.6 Syntax für Lambda-Ausdrücke
Lambda-Ausdrücke haben wie Methoden mögliche Parameter- und Rückgabewerte. Die Java-Grammatik für die Schreibweise von Lambda-Ausdrücken sieht ein paar nützliche syntaktische Abkürzungen vor.
Ausführliche Schreibweise
Lambda-Ausdrücke lassen sich auf unterschiedliche Art und Weise schreiben, da es für diverse Konstruktionen Abkürzungen gibt. Eine Form, die jedoch immer gilt, ist:
( LambdaParameter ) -> { Anweisungen }
Der Lambda-Parameter besteht (voll ausgeschrieben) wie ein Methodenparameter aus:
dem Typ,
dem Namen und
optionalen Modifizierern
Der Parametername öffnet einen neuen Gültigkeitsbereich für eine Variable, wobei der Parametername keine anderen Namen von lokalen Variablen überlagern darf. Hier verhält sich die Lambda-Parametervariable wie eine neue Variable aus einem inneren Block und nicht wie eine Variable aus einer inneren Klasse, wo die Sichtbarkeit anders ist.
[zB] Beispiel
Folgendes ergibt einen Compilerfehler im Lambda-Ausdruck, weil s schon deklariert ist – die Parametervariable vom Lambda-Ausdruck muss »frisch« sein:
String s = "Make Donald Drumpf Again";
Comparator<String> c = (String s, String t) -> { ... }; //
Abkürzung 1: Typ-Inferenz (impliziter Typ)
Der Java-Compiler kann viele Typen aus dem Kontext ablesen, was Typ-Inferenz genannt wird. Wir kennen so etwas vom Diamant-Operator, wenn wir etwa schreiben:
List<String> list = new ArrayList<>()
Sind für den Compiler genug Typinformationen verfügbar, dann erlaubt der Compiler bei Lambda-Ausdrücken eine Abkürzung. Bei der Deklaration
Comparator<String> c =
(String s1, String s2) -> { return s1.trim().compareTo( s2.trim() ); };
ist dem Compiler dank Typ-Inferenz klar, dass rechts vom Gleichheitszeichen ein Ausdruck vom Typ Comparator<String> kommen muss und die Comparator-Methode compare(…) zwei Parameter vom Typ String besitzt. Daher funktioniert die folgende Abkürzung:
Comparator<String> c = (s1, s2) -> { return s1.trim().compareTo( s2.trim() ); };
[»] Hinweis
Die Parameterliste enthält entweder explizit deklarierte Parametertypen oder implizite Inferred-Typen. Eine Mischung ist nicht erlaubt, der Compiler blockt so etwas wie (String s1, s2) oder (s1, String s2) mit einer Fehlermeldung ab.
Wenn der Compiler die Typen ablesen kann, sind die Parametertypen optional. Aber Typ-Inferenz ist nicht immer möglich, weshalb die Abkürzung nicht immer möglich ist. Außerdem hilft die explizite Schreibweise auch der Lesbarkeit: Kurze Ausdrücke sind nicht unbedingt die verständlichsten.
[»] Hinweis
Der Compiler liest aus den Typen ab, ob alle Eigenschaften vorhanden sind. Die Typen sind dabei entweder explizit oder implizit gegeben.
Comparator<String> sc = (a, b) ->
{ return Integer.compare( a.length(), b.length() ); };
Comparator<BitSet> bc = (a, b) ->
{ return Integer.compare( a.length(), b.length() ); };
Die Klassen String und BitSet besitzen beide die Methode length(), daher ist der Lambda-Ausdruck korrekt. Der gleiche Lambda-Code im Quellcode lässt sich für zwei völlig verschiedene Klassen einsetzen, die überhaupt keine Gemeinsamkeiten haben, nur dass sie zufällig beide eine Methode namens length() besitzen.
Abkürzung 2: Der Lambda-Rumpf ist entweder ein einzelner Ausdruck oder ein Block
Besteht der Rumpf eines Lambda-Ausdrucks nur aus einem einzelnen Ausdruck, kann eine verkürzte Schreibweise die Blockklammern und das Semikolon einsparen. Statt
( LambdaParameter ) -> { return Ausdruck; }
( LambdaParameter ) -> Ausdruck
Lambda-Ausdrücke mit einer return-Anweisung im Rumpf kommen häufig vor, da dies den typischen Funktionen entspricht. Somit ist es eine willkommene Verkürzung, wenn die abgekürzte Syntax für Lambda-Ausdrücke lediglich den Ausdruck fordert, der dann die Rückgabe bildet. Tabelle 12.3 zeigt zwei Beispiele.
Lange Schreibweise | Abkürzung |
|---|---|
(s1, s2) -> | (s1, s2) -> |
(a, b) -> { return a + b; } | (a, b) -> a + b |
Tabelle 12.3 Ausführliche und abgekürzte Schreibweise
[»] Hinweis
Die Schreibweise mit den geschweiften Klammern und den Rückgabe-Ausdrücken kann nicht gemischt werden. Entweder gibt es einen Block geschweifter Klammern und return oder keine Klammern und kein return-Schlüsselwort. Falsche Mischungen ergeben Fehler:
Comparator<String> c;
c = (s1, s2) -> { s1.trim().compareTo( s2.trim() ) }; //
c = (s1, s2) -> return s1.trim().compareTo( s2.trim() ); //
Würden wir in (1) ein explizites return nutzen, wäre alles in Ordnung; würde bei (2) das return wegfallen, wäre die Zeile auch compilierbar.
void-kompatibel
Ausdrücke können in Java auch zu void ausgewertet werden, sodass ohne Probleme ein Aufruf wie System.out.println() in der kompakten Schreibweise ohne Block gesetzt werden kann. Das heißt, wenn Lambda-Ausdrücke mit der kurzen Ausdruckssyntax eingesetzt werden, können diese Ausdrücke etwas zurückgeben, sie müssen es aber nicht.
Lange Schreibweise | Abkürzung |
|---|---|
() -> { System.out.println(); } | () -> System.out.println() |
(s) -> { System.out.println(s); } | (s) -> System.out.println(s) |
Tabelle 12.4 Ausführliche und abgekürzte Schreibweise
Ob Lambda-Ausdrücke eine Rückgabe haben, drücken zwei Begriffe aus:
void-kompatibel: Der Lambda-Rumpf gibt kein Ergebnis zurück, entweder weil der Block kein return enthält oder ein return ohne Rückgabe oder weil ein void-Ausdruck in der verkürzten Schreibweise eingesetzt wird. Der Lambda-Ausdruck () -> System.out.println() ist also void-kompatibel, genauso wie () -> {}.
wertkompatibel: Der Rumpf beendet den Lambda-Ausdruck mit einer return-Anweisung, die einen Wert zurückgibt, oder besteht aus der kompakten Schreibweise mit einer Rückgabe ungleich void.
Eine Mischung aus void- und wertkompatibel ist nicht erlaubt und führt wie bei Methoden zu einem Compilerfehler.[ 219 ](Wohl aber gibt es wie bei { throw new RuntimeException(); } Ausnahmen, bei denen Lambda-Ausdrücke beides sind. )
 Eclipse kann in den frühen Versionen Lambda-Ausdrücke nicht debuggen. Hier hilft es nur, erstens die Block-Syntax zu verwenden und zweitens den Block nach einem Zeilenumbruch zu starten. IntelliJ kommt damit viel besser klar.
Eclipse kann in den frühen Versionen Lambda-Ausdrücke nicht debuggen. Hier hilft es nur, erstens die Block-Syntax zu verwenden und zweitens den Block nach einem Zeilenumbruch zu starten. IntelliJ kommt damit viel besser klar.
Abkürzung 3: Einzelner Identifizierer statt Parameterliste und Klammern
Besteht die Parameterliste
nur aus einem einzelnen Identifizierer und ist
der Typ durch Typ-Inferenz klar,
dann können die runden Klammern wegfallen.
Lange Schreibweise | Typen inferred | Vollständig abgekürzt |
|---|---|---|
(String s) -> s.length() | (s) -> s.length() | s -> s.length() |
(int i) -> Math.abs( i ) | (i) -> Math.abs( i ) | i -> Math.abs( i ) |
Tabelle 12.5 Unterschiedlicher Grad von Abkürzungen
Kommen alle Abkürzungen zusammen, lässt sich etwa die Hälfte an Code einsparen. Aus
(int i) -> { return Math.abs( i ); } wird einfach i -> Math.abs( i ).
[»] Syntax-Hinweis
Nur bei genau einem Lambda-Parameter können die runden Klammern weggelassen werden, da es sonst Mehrdeutigkeiten gibt, für die es wieder komplexe Regeln zur Auflösung geben müsste. Heißt es etwa foo( k, v -> { … } ), ist unklar, ob foo zwei Parameter deklariert. Ist das zweite Argument ein Lambda-Ausdruck oder handelt es sich um nur genau einen Parameter, wobei dann ein Lambda-Ausdruck übergeben wird, der selbst zwei Parameter deklariert? Um Problemen wie diesem aus dem Weg zu gehen, können Entwickler auf den ersten Blick sehen, dass foo( k, v -> { … } ) eindeutig für zwei Argumente steht und foo( (k, v) -> { … } ) nur ein Argument übergibt.
Abkürzung 4: Typ-Inferenz durch var
In Lambda-Ausdrücken kann ebenfalls var eingesetzt werden.[ 220 ](Diese Möglichkeit ist neu in Java 11 dank http://openjdk.java.net/jeps/323. ) Eine Mischung aus expliziten Typen, impliziten Typen und var-Typen ist nicht gestattet:
Comparator<String> c0 = (var x, var y) -> 0;
Comparator<String> c1 = (x, var y) -> 0; //
Comparator<String> c2 = (var x, y) -> 0; //
Comparator<String> c3 = (int x, var y) -> 0; //
Comparator<String> c4 = (int x, y) -> 0; //
Eigentlich ergibt der Einsatz von var bei der Möglichkeit von impliziten Typen wenig Sinn. Allerdings ist er erstens konsistent und zweitens dann nützlich, wenn eine Annotation an die Variable kommt, denn hierfür ist die Typangabe notwendig.
Unbenutzte Parameter in Lambda-Ausdrücken
Es kommt vor, dass ein Lambda-Ausdruck eine funktionale Schnittstelle implementiert, aber nicht jeder Parameter von Interesse ist. Als Beispiel schauen wir uns eine funktionale Schnittstelle aus der Java SE an (etwas vereinfacht):
interface Consumer<T> { void accept( T t ); }
Ein Konsument, der das Argument in Hochkommata ausgibt, sieht so aus:
Consumer<String> printQuoted = s -> System.out.printf( "'%s'", s );
printQuoted.accept( "Chris" ); // 'Chris'
Was ist nun, wenn ein Konsument auf das Argument gar nicht zugreifen möchte, weil zum Beispiel die aktuelle Zeit ausgegeben wird, aber der Code als Consumer vorliegen muss?
Consumer<String> printNow =
s -> System.out.print( System.currentTimeMillis() );
Die Variable s in der Lambda-Parameterliste ist ungenutzt und wird vom Compiler auch als »unused« bemängelt.
Es gibt für unbenutzte Parameter keine spezielle Schreibweise und keine Möglichkeit, den Variablennamen wegzulassen und nur den Typ anzugeben.
Es gibt drei Ansätze, um mit der Situation umzugehen:
Der eine Ansatz ist, für den Lambda-Parameter den Typnamen anzugeben – der wird dann als Variablenname verwendet, aber das ist vom Compiler her in Ordnung:
Consumer<String> printNow =
String -> System.out.print( System.currentTimeMillis() );Die Schreibweise ist ungewohnt, denn großgeschriebene Variablennamen zu verwenden, die zudem so heißen wie ein Typ, ist ein Bruch der Konvention; es funktioniert aber. Genutzt werden sollte der Lambda-Parameter aber nicht, String -> System.out.print(String) sieht einfach nur falsch aus.
Die zweite Möglichkeit kann darin bestehen, zwei Unterstriche zu verwenden. Die Nutzung eines Unterstrichs für einen Bezeichner ist seit Java 9 verboten, könnte aber in späteren Java-Versionen wieder eingeführt werden:
Consumer<String> printNow = __ -> System.out.print( System.currentTimeMillis() );
Die dritte Variante kann nicht immer eingesetzt werden, sondern nur dann, wenn es eine Methode gibt, die über eine Methodenreferenz angesprochen werden kann; in dieser Schreibweise gibt es keine Lambda-Parameter. Methodenreferenzen schauen wir in Abschnitt 12.2 genauer an.
12.1.7 Die Umgebung der Lambda-Ausdrücke und Variablenzugriffe
Ein Lambda-Ausdruck »sieht« seine Umgebung genauso wie der Code, der vor oder nach dem Lambda-Ausdruck steht. Insbesondere hat ein Lambda-Ausdruck vollständigen Zugriff auf alle Eigenschaften der Klasse, genauso wie auch der einschließende äußere Block sie hat.
Lesender Zugriff auf finale, lokale Variablen bzw. Parametervariablen
Lambda-Ausdrücke können problemlos auf Objektvariablen und Klassenvariablen lesend und schreibend zugreifen. Auf lokale Variablen sowie Methoden- oder Exception-Parameter hat ein Lambda-Ausdruck jedoch nur lesenden Zugriff, und die Variablen müssen (effektiv) final sein. Liegt ein Lambda-Ausdruck zum Beispiel in einer Schleife, kann er nicht auf den Schleifenzähler zugreifen, da sich dieser bei jeder Iteration ändert. (Anders sieht das bei der Variablen in der erweiterten for-Schleife aus: Auf sie kann ein Lambda-Ausdruck zugreifen.)
Dass eine Variable final ist, muss nicht extra mit einem Modifizierer geschrieben werden, aber sie muss effektiv final (engl. effectively final) sein. Effektiv final ist eine Variable, wenn sie nach der Initialisierung nicht mehr beschrieben wird. Der Modifizierer final kann entfallen.
Ein Beispiel: Der Benutzer soll über eine Eingabe die Möglichkeit bekommen, zu bestimmen, ob String-Vergleiche mit unserem trimmenden Comparator unabhängig von der Groß-/Kleinschreibung stattfinden sollen:
Listing 12.2 src/main/java/com/tutego/insel/lambda/TrimIgnoreCaseCompare.java, main
public static void main( String[] args ) {
/*final*/ boolean ignoreCase = new Scanner( System.in ).nextBoolean();
Comparator<String> c = (s1, s2) -> ignoreCase ?
s1.trim().compareToIgnoreCase( s2.trim() ) :
s1.trim().compareTo( s2.trim() );
String[] words = { "M", "\nSkyfall", " Q", "\t\tAdele\t" };
Arrays.sort( words, c );
System.out.println( Arrays.toString( words ) );
}
Ob ignoreCase von uns final gesetzt wird oder nicht, ist egal, denn die Variable wird hier effektiv final verwendet. Natürlich kann es nicht schaden, final als Modifizierer immer davorzusetzen, um dem Leser des Codes diese Tatsache bewusst zu machen.
Neu eingeschobene Lambda-Ausdrücke, die auf lokale Variablen oder Parametervariablen zugreifen, können also im Nachhinein zu Compilerfehlern führen. Folgendes Segment ist ohne Lambda-Ausdruck korrekt:
boolean ignoreCase = new Scanner( System.in ).nextBoolean(); // 1
... // 2
ignoreCase = true; // 3
Schiebt sich zwischen Zeile 1 und 3 nachträglich ein Lambda-Ausdruck, der auf ignoreCase zugreift, gibt es anschließend einen Compilerfehler. Allerdings liegt der Fehler nicht in Zeile 3, sondern beim Lambda-Ausdruck, denn die Variable ignoreCase ist nach der Änderung nicht mehr effektiv final, was sie aber sein müsste, um in dem Lambda-Ausdruck verwendet zu werden.
Schreibender Zugriff auf lokale Variablen bzw. Parametervariablen? *
Lambda-Ausdrücke können lokale Variablen nur lesen und nicht beschreiben – das Gleiche gilt übrigens für innere anonyme Klassen. Der Grund hat etwas damit zu tun, wo Variablen gespeichert werden: Objekt- und statische Variablen »leben« auf dem Heap, lokale Variablen und Parameter »leben« auf dem Stack. Wenn nun Threads ins Spiel kommen, ist es nicht unüblich, dass unterschiedliche Threads die Variablen vom Heap nutzen; dafür gibt es Synchronisationsmöglichkeiten. Allerdings kann ein Thread nicht auf lokale Variablen eines anderen Threads zugreifen, denn ein Thread hat erst einmal keinen Zugriff auf den Stack-Speicher eines anderen Threads. Grundsätzlich wäre das möglich, allerdings wollten die Oracle-Entwickler diesen Pfad nicht beschreiten. Beim Lesezugriff wird tatsächlich eine Kopie angelegt, sodass sie für einen anderen Thread sichtbar ist.
Die Einschränkung, dass äußere lokale Variablen von Lambda-Ausdrücken nur gelesen werden können, ist an sich etwas Gutes, denn die Beschränkung minimiert Fehler bei nebenläufiger Ausführung von Lambda-Ausdrücken: Arbeiten mehrere Threads Lambda-Ausdrücke ab und beschreiben diese eine lokale Variable, müsste andernfalls eine Thread-Synchronisation her.
Grundsätzlich verbietet nicht jede Programmiersprache das Schreiben von lokalen Variablen aus Lambda-Ausdrücken heraus. In C# kann ein Lambda-Ausdruck lokale Variablen beschreiben, sie »leben« dann nicht mehr auf dem Stack.
Mit Behältern wie einem Array oder den speziellen AtomicXXX-Klassen aus dem java.util.concurrent.atomic-Paket lässt sich das Problem im Prinzip lösen. Denn greift ein Lambda-Ausdruck etwa auf das Array boolean[] ignoreCase = new boolean[1]; zu, so ist die Variable ignoreCase selbst final, aber ignoreCase[0] = true; ist erlaubt, denn es ist ein Schreibzugriff auf das Array, nicht auf die Variable ignoreCase. Je nach Code besteht jedoch die Gefahr, dass Lambda-Ausdrücke parallel ausgeführt werden. Wird etwa ein Lambda-Ausdruck mit Veränderung auf diesem Array-Inhalt parallel ausgeführt, so ist der Zugriff nicht synchronisiert, und das Ergebnis kann »kaputt« sein, denn paralleler Zugriff auf Variablen muss immer koordiniert vorgenommen werden.
Implementierungsdetails und Ausnahmen in Lambda-Ausdrücken *
Als die Compilerentwickler einen Prototyp für Lambda-Ausdrücke bauten, setzten sie diese technisch mit geschachtelten Klassen um. Doch das war nur in der Testphase so, denn geschachtelte Klassen sind für die JVM komplette Klassen und schwergewichtig. Das Laden und Initialisieren von Klassen ist relativ teuer und wäre bei den vielen kleinen Lambda-Ausdrücken ein großer Overhead.
Aktuell setzt der Java-Compiler Lambda-Ausdrücke mit Methoden um. Wenn wir das JDK-Werkzeug javap auf den Bytecode mit dem Aufruf javap -p TrimIgnoreCaseCompare anwenden, folgt, etwas abgekürzt:
public class TrimIgnoreCaseCompare {
public TrimIgnoreCaseCompare();
public static void main(String[]);
private static int lambda$0(boolean, String, String);
}
Der Rumpf der privaten statischen Methode lambda$0(…) enthält den Codeblock ignoreCase ? s1.trim() … . Die JVM als Aufrufer der Methode übergibt den Inhalt der ignoreCase-Variablen. Da es in Java als Parameterübergabe-Mechanismus nur Call by Value gibt, eine Kopie von ignoreCase. Selbst wenn die Methode die Parametervariable ändern würde, käme die neue Belegung niemals aus der Methode heraus.
Dass Lambda-Ausdrücke in Methoden umgesetzt werden, ist auch bei Ausnahmen im Stack-Trace gut sichtbar. Lassen wir den Comparator mit
Comparator<String> c = (s1, s2) -> 1 / 0;
eine ArithmeticException auslösen.
In der Ausführung folgt:
Exception in thread "main" java.lang.ArithmeticException: / by zero
at TrimIgnoreCaseCompare.lambda$0(TrimIgnoreCaseCompare.java:6)
at java.base/java.util.TimSort.countRunAndMakeAscending(TimSort.java:355)
at java.base/java.util.TimSort.sort(TimSort.java:220)
at java.base/java.util.Arrays.sort(Arrays.java:1442)
at TrimIgnoreCaseCompare.main(TrimIgnoreCaseCompare.java:8)
Die vom Compiler angelegte Methode lambda$0(…) lässt sich also gut ablesen.
Jetzt haben wir gesehen, wohin der Code des Lambda-Ausdrucks geht, allerdings wissen wir noch nicht, wie er aufgerufen wird. Denn wenn wir Arrays.sort(words, (s1, s2) -> …) schreiben, muss die JVM für den Lambda-Ausdruck die lambda$0(…)-Methode aufrufen. Bis zum Methodenauruf ist es noch ein weiter Weg. Hier greift der Compiler auf einen speziellen Bytecode invokedynamic zurück. Das hat den großen Vorteil, dass die Laufzeitumgebung viel Gestaltungsraum in der Optimierung hat. Geschachtelte Klassen sind nur eine mögliche technische Umsetzung für Lambda-Ausdrücke, invokedynamic ist sozusagen die deklarative Variante, und geschachtelte Klassen sind die imperative, ausprogrammierte Spielart. Letztendlich ist der Overhead mit invokedynamic gering, und Programmcode von geschachtelten Klassen hin zu Lambda-Ausdrücken zu refaktorisieren, führt zu kleinen Bytecodedateien. Von der Performance her unterscheiden sich Lambda-Ausdrücke und die Implementierung funktionaler Schnittstellen und Klassen nicht, eher ist die Optimierung auf der Seite der JVM zu finden, die es mit weniger Klassendateien zu tun hat. Umgekehrt bedeutet das auch: Wenn Entwickler ihre alte, vorhandene Implementierung von funktionalen Schnittstellen durch Lambda-Ausdrücke ersetzen, wird der Bytecode kompakter, da ein kleines invokedynamic viel kürzer ist als komplexe neue Klassendateien.
Namensräume
Deklariert eine innere anonyme Klasse Variablen innerhalb der Methode, so sind diese immer »neu«, das heißt, die neuen Variablen überlagern vorhandene lokale Variablen aus dem äußeren Kontext. Die Variable ignoreCase kann im Rumpf von compare(…) zum Beispiel problemlos neu deklariert werden:
boolean ignoreCase = true;
Comparator<String> c = new Comparator<String>() {
@Override public int compare( String s1, String s2 ) {
boolean ignoreCase = false; // völlig ok
return ...
}
};
In einem Lambda-Ausdruck ist das nicht möglich, und Folgendes führt zu einer Fehlermeldung »variable ignoreCase ist already defined« des Compilers:
boolean ignoreCase = true;
Comparator<String> c = (s1, s2) -> {
boolean ignoreCase = false; //
return ...
}
this-Referenz
Ein Lambda-Ausdruck unterscheidet sich von einer inneren (anonymen) Klasse auch darin, worauf die this-Referenz verweist:
Beim Lambda-Ausdruck zeigt this immer auf das Objekt, in das der Lambda-Ausdruck eingebettet ist.
Bei einer inneren Klasse referenziert this die innere Klasse, und die ist ein komplett neuer Typ.
Folgendes Beispiel macht das deutlich:
Listing 12.3 src/main/java/com/tutego/insel/lambda/InnerVsLambdaThis.java, Ausschnitt
class InnerVsLambdaThis {
InnerVsLambdaThis() {
Runnable lambdaRun = () -> System.out.println( this.getClass().getName() );
Runnable innerRun = new Runnable() {
@Override public void run() { System.out.println( this.getClass().getName()); }
};
lambdaRun.run(); // InnerVsLambdaThis
innerRun.run(); // InnerVsLambdaThis$1
}
public static void main( String[] args ) {
new InnerVsLambdaThis();
}
}
Als Erstes nutzen wir this in einem Lambda-Ausdruck im Konstruktor der Klasse InnerVsLambdaThis. Damit referenziert this das neu gebaute InnerVsLambdaThis-Objekt. Bei der inneren Klasse referenziert this ein anderes Exemplar, und zwar vom Typ Runnable. Da es bei anonymen Klassen keinen Namen hat, trägt es lediglich die Kennung InnerVsLambdaThis$1.
Rekursive Lambda-Ausdrücke
Lambda-Ausdrücke können auf sich selbst verweisen. Da aber ein this zur Selbstreferenz nicht funktioniert, ist ein kleiner Umweg nötig. Erst muss eine Objekt- oder eine Klassenvariable deklariert werden, dann muss dieser Variablen ein Lambda-Ausdruck zugewiesen werden, und danach kann der Lambda-Ausdruck auf diese Variable zugreifen und einen rekursiven Aufruf starten. Für den Klassiker der Fakultät sieht das so aus:
Listing 12.4 src/main/java/com/tutego/insel/lambda/RecursiveFactLambda.java, Ausschnitt
public class RecursiveFactLambda {
public static IntFunction<Integer> fact =
n -> (n == 0) ? 1 : n * RecursiveFactLambda.fact.apply( n - 1 );
public static void main( String[] args ) {
System.out.println( fact.apply( 5 ) ); // 120
}
}
IntFunction ist eine funktionale Schnittstelle aus dem Paket java.util.function mit einer Operation T apply(int i). Dabei ist T ein generischer Rückgabetyp, den wir hier mit Integer belegt haben. Es funktioniert übrigens nicht, n * fact.apply( n - 1 ) zu schreiben, da der Compiler dann meldet: »Cannot reference a field before it is defined«.
fact hätte genauso gut als normale Methode deklariert werden können. Großartige Vorteile bietet die Schreibweise mit Lambda-Ausdrücken hier nicht. Zumal jetzt auch der Begriff anonyme Methode nicht mehr so richtig passt, da der Lambda-Ausdruck ja doch einen Namen hat, nämlich fact.
Lambda-Ausdücke können nicht auf eigene Default-Methoden zurückgreifen
Eine funktionale Schnittstelle darf nur genau eine abstrakte Methode haben, kann aber weitere statische und Default-Methoden beinhalten. Implementiert eine Klasse eine funktionale Schnittstelle, so kann die Methode auf Default-Methoden zurückgreifen.
Listing 12.5 src/main/java/com/tutego/insel/lambda/ InnerVsLambdaDefaultMethod.java, Ausschnitt
class TruePredicate implements Predicate<Object> {
@Override public boolean test( Object o ) {
return negate().test( o );
}
}
Ein Lambda-Ausdruck kann das nicht, auch nicht mit Tricks wie Predicate.this:
Predicate<Object> truePredicate = o -> negate().test( o ); //
Ein echtes Problem stellt das in der Praxis nicht da, und es verhindert sogar Fehler. Default-Methoden greifen fast ausschließlich auf die abstrakten Methoden zurück und »können« alleine nichts. An der negate()-Methode von Predicate lässtg sich das gut ablesen:
Listing 12.6 java/util/function/Predicate.java, Ausschnitt
default Predicate<T> negate() {return (t) -> !test(t);}
nagate() ruft wieder test(…) auf. Wird in der Implementierung von test(…) die Methode negate() aufgerufen, folgt eine Endlosrekursion.
12.1.8 Ausnahmen in Lambda-Ausdrücken
Lambda-Ausdrücke sind Implementierungen von funktionalen Schnittstellen, und bisher haben wir noch nicht die Frage betrachtet, was passiert, wenn der Codeblock vom Lambda-Ausdruck eine Ausnahme auslöst, und wer diese auffangen muss.
Ausnahmen im Codeblock eines Lambda-Ausdrucks
In java.util.function gibt es eine funktionale Schnittstelle Predicate, deren Deklaration im Kern wie folgt ist:
public interface Predicate<T> { boolean test( T t ); }
Ein Predicate führt einen Test durch und liefert wahr oder falsch als Ergebnis. Ein Lambda-Ausdruck kann diese Schnittstelle implementieren. Nehmen wir an, wir wollten testen, ob eine Datei die Länge 0 hat, um etwa Dateileichen zu finden. In einer ersten Idee greifen wir auf die existierende Files-Klasse zurück, die size(…) anbietet:
Predicate<Path> isEmptyFile = path -> Files.size( path ) == 0; //
Das Problem dabei ist, dass Files.size(…) eine IOException auslöst, die behandelt werden muss, und zwar nicht vom Block, in dem der Lambda-Ausdruck als Ganzes steht, sondern vom Code im Lambda-Ausdruck selbst. Das schreibt der Compiler so vor. Folgendes ist keine Lösung:
try {
Predicate<Path> isEmptyFile = path -> Files.size( path ) == 0; //
} catch ( IOException e ) { ... }
sondern nur:
Predicate<Path> isEmptyFile = path -> {
try {
return Files.size( path ) == 0;
} catch ( IOException e ) { return false; }
};Die Eigenschaft, die Java fehlt, nennt sich Exception-Transparenz, und hier ist deutlich der Unterschied zwischen geprüften und ungeprüften Ausnahmen zu sehen. Bei der Exception-Transparenz wäre keine Ausnahmebehandlung im Lambda-Ausdruck nötig und an einer übergeordneten Stelle möglich. Doch da diese Möglichkeit in Java fehlt, bleibt uns nur übrig, geprüfte Ausnahmen in Lambda-Ausdrücken direkt zu behandeln.
Funktionale Schnittstellen mit throws-Klausel
Ungeprüfte Ausnahmen können immer auftreten und führen (nicht abgefangen) wie üblich zum Abbruch des Threads. Eine throws-Klausel an den Methoden/Konstruktoren ist dafür nicht nötig. Doch können funktionale Schnittstellen eine throws-Klausel mit geprüften Ausnahmen deklarieren, und die Implementierung einer funktionalen Schnittstelle kann logischerweise geprüfte Ausnahmen auslösen.
Eine Deklaration wie Callable aus dem Paket java.util.concurrent macht das deutlich:
public interface Callable<V> {
V call() throws Exception;
}
Das könnte durch folgenden Lambda-Ausdruck realisiert werden:
Callable<Integer> randomDice = () -> (int)(Math.random() * 6) + 1;
Der Aufruf von call() auf einem randomDice muss mit einer Ausnahmebehandlung einhergehen, da call() eine Exception auslöst, etwa so:
try {
System.out.println( randomDice.call() );
System.out.println( randomDice.call() );
}
catch ( Exception e ) { ... }
Dass der Aufrufer die Ausnahme behandeln muss, ist klar. Die Deklaration des Lambda-Ausdrucks enthält keinen Hinweis auf die Ausnahme – das ist ein Unterschied zum vorangegangenen Abschnitt.
[+] Designtipp
Ausnahmen in Methoden funktionaler Schnittstellen schränken den Nutzen stark ein, und daher löst keine der funktionalen Schnittstellen aus etwa java.util.function eine geprüfte Ausnahme aus. Der Grund ist einfach, denn jeder Methodenaufrufer müsste sonst entweder die Ausnahme weiterleiten oder behandeln.[ 221 ](Von Callable gibt es zwar Nutzer, die mit Nebenläufigkeit (daher das Paket java.util.concurrent) in Zusammenhang stehen. Sonst gibt es aber keine weiteren Verwendungen in der Java-Bibliothek, von zwei Beispielen aus javax.tools abgesehen. Mit java.util.function.Supplier existiert eine entsprechende Alternative ohne throws-Klausel. )
Um die Einschränkungen und Probleme mit einer throws-Klausel noch etwas deutlicher zu machen, stellen wir uns vor, dass die funktionale Schnittstelle Predicate an der Operation ein throws Exception (vom Sinn des Typs Exception an sich einmal abgesehen) enthält:
interface Predicate<T> { boolean test( T t ) throws Exception; } // Was wäre, wenn?
Die Konsequenz wäre, dass jeder Aufrufer von test(…) nun seinerseits die Exception in die Hände bekäme und sie auffangen oder weiterleiten müsste. Leitet der test(…)-Aufrufer mit throws Exception die Ausnahme weiter nach oben, bekommen wir plötzlich an allen Stellen ein throws Exception in die Methodensignatur, was auf keinen Fall gewünscht ist. Zum Beispiel enthält Collection (eine Schnittstelle, die unsere bekannte ArrayList implementiert) eine Deklaration von removeIf(Predicate filter); hier müsste sich dann removeIf(…) – das letztendlich filter.test(…) aufruft – mit der Ausnahme herumärgern, und removeIf(Predicate filter) throws Exception ist keine gute Sache.
Von geprüft nach ungeprüft
Geprüfte Ausnahmen sind in Lambda-Ausdrücken nicht schön. Eine Lösung ist, Code, der geprüfte Ausnahmen auslöst, zu verpacken und die geprüfte Ausnahme in eine ungeprüfte einzubetten. Das kann etwa so aussehen:
Listing 12.7 src/main/java/com/tutego/insel/lambda/PredicateWithException.java, Ausschnitt
public class PredicateWithException {
@FunctionalInterface
public interface ExceptionalPredicate<T,E extends Exception> {
boolean test( T t ) throws E;
}
public static <T> Predicate<T> asUncheckedPredicate(
ExceptionalPredicate<T,Exception> predicate ) {
return t -> {
try {
return predicate.test( t );
}
catch ( Exception e ) {
throw new RuntimeException( e.getMessage(), e );
}
};
}
public static void main( String[] args ) {
Predicate<Path> isEmptyFile =
asUncheckedPredicate( path -> Files.size( path ) == 0 );
System.out.println( isEmptyFile.test( Paths.get( "c:/" ) ) );
}
}
Die Schnittstelle ExceptionalPredicate ist ein Prädikat mit optionaler Ausnahme. In der eigenen Hilfsmethode asUncheckedPredicate(ExceptionalPredicate) nehmen wir so ein ExceptionalPredicate an und packen es in ein Predicate, das die Methode zurückgibt. Geprüfte Ausnahmen werden in eine ungeprüfte Ausnahme vom Typ RuntimeException gesetzt. Somit muss Predicate keine geprüfte Ausnahme weiterleiten, was es ja laut Deklaration auch nicht kann.
Die Java-Bibliothek selbst bringt keine Standardmethoden für Einbettungen dieser Art mit. Es gibt nur eine interne Methode, die etwas Vergleichbares tut:
Listing 12.8 java.nio.file.Files.java, asUncheckedRunnable(…)
/**
* Convert a Closeable to a Runnable by converting checked IOException
* to UncheckedIOException
*/
private static Runnable asUncheckedRunnable( Closeable c ) {
return () -> {
try {
c.close();
}
catch ( IOException e ) {
throw new UncheckedIOException( e );
}
};
}
Hier kommt die Klasse UncheckedIOException zum Einsatz. Diese ist eine ungeprüfte Ausnahme, die als Wrapper-Klasse für Ein-/Ausgabefehler genutzt wird. Wir finden die UncheckedIOException etwa bei lines() von BufferedReader bzw. Files, die einen Stream<String> mit Zeilen liefert – geprüfte Ausnahmen sind hier nur im Weg.
12.1.9 Klassen mit einer abstrakten Methode als funktionale Schnittstelle? *
Als die Entwickler der Sprache Java die Lambda-Ausdrücke diskutierten, stand auch die Frage im Raum, ob abstrakte Klassen, die nur über eine abstrakte Methode verfügen, ebenfalls für Lambda-Ausdrücke genutzt werden können.[ 222 ](Früher wurde hier die Abkürzung SAM (Single Abstract Method) genutzt. ) Die Entwickler entschieden sich dagegen, unter anderem deswegen, weil bei der Implementierung von Schnittstellen die JVM weitreichende Optimierungen vornehmen kann. Und bei Klassen wird das schwierig. Das liegt auch daran, dass ein Konstruktor umfangreiche Initialisierungen mit Seiteneffekten vornimmt (die Konstruktoren aller Oberklassen nicht zu vergessen) sowie Ausnahmen auslösen könnte. Gewünscht ist aber nur die Ausführung einer Implementierung der funktionalen Schnittstelle und kein anderer Code.
Es gibt nun im JDK einige abstrakte Klassen, die genau eine abstrakte Methode vorschreiben, etwa java.util.TimerTask. Solche Klassen können nicht über einen Lambda-Ausdruck realisiert werden. Hier müssen Entwickler weiterhin zu Klassenimplementierungen greifen, und die kürzeste Lösung ist eine innere anonyme Klasse. Eigene Hilfsklassen können natürlich den Code etwas abkürzen, aber eben nur mithilfe einer eigenen Implementierung.
Wer abstrakte Methoden mit Lambda-Ausdrücken implementieren möchte, kann mit Hilfsklassen arbeiten. Denn wenn eine Hilfsklasse funktionale Schnittstellen einsetzt, so können Lambda-Ausdrücke wieder ins Spiel kommen, indem die Implementierung der abstrakten Methode an den Lambda-Ausdruck weiterleitet. Nehmen wir das Beispiel für TimerTask, und gehen wir zwei unterschiedliche Strategien der Implementierung durch. Mit Delegation sieht das so aus:
Listing 12.9 src/main/java/com/tutego/insel/lambda/TimerTaskLambda.java, Ausschnitt
class TimerTaskLambda {
public static TimerTask createTimerTask( Runnable runnable ) {
return new TimerTask() {
@Override public void run() { runnable.run(); }
};
}
public static void main( String[] args ) {
new Timer().schedule( createTimerTask( () -> System.out.println("Hi") ), 500 );
}
}
Mit Vererbung erhalten wir:
public class LambdaTimerTask extends TimerTask {
private final Runnable runnable;
public LambdaTimerTask( Runnable runnable ) {
this.runnable = runnable;
}
@Override public void run() { runnable.run(); }
}
Der Aufruf erfolgt dann statt über createTimerTask(…) mit dem Konstruktor:
new Timer().schedule( new LambdaTimerTask( () -> System.out.println("Hi") ), 500 );
 Java ist auch eine Insel
Java ist auch eine Insel Jetzt Buch bestellen
Jetzt Buch bestellen


