
Thema der Woche: Das HTTP-Protokoll
Über HTTP tauschen Client (etwa Browser) und Server Metadaten und Nutzdaten aus.
- Ließ http://de.wikipedia.org/wiki/Hypertext_Transfer_Protocol
- Um von Java auf einen Web-Server zuzugreifen kann die eingebauten Klasse URLConnection verwendet werden. Lies http://openbook.galileocomputing.de/javainsel8/javainsel_18_003.htm#mj9fa6dd9cce4e5c99afe7c4df48d14b57.
- Was ist der Unterschied zwischen URLConnection und HttpURLConnection? Wer liefert HttpURLConnection? Warum?
- Unterstützt (Http)URLConnection alle Spielereien vom HTTP-Protokoll oder gibt es weiße Flecken?
- Insbesondere POST-Aufrufe sind etwas mühselig, sodass mit http://hc.apache.org/httpcomponents-client/index.html eine gute Alternative existiert. Schreibe ein kleines Beispiel mit einem GET, was über Parameter die Yahoo Geo-Code API http://developer.yahoo.com/maps/rest/V1/geocode.html nutzt.
- Eine neuere Alternative ist der http://github.com/ning/async-http-client. Ließ die Kurzeinführung und implementierte das gleiche Geo-Beispiel mit der async-http-client-API.
Die ersten Schritte mit JAXB
JAXB ist eine API zum Übertragen von Objektzuständen auf XML-Dokumente und umgedreht. Anders als eine manuelle Abbildung von Java-Objekten auf XML-Dokumente oder das Parsen von XML-Strukturen und Übertragen der XML-Elemente auf Geschäftsobjekte arbeitet JAXB automatisch. Die Übertragungsregeln definieren Annotationen, die Entwickler selbst an die JavaBeans setzten können, aber JavaBeans werden gleich zusammen mit den Annotationen von einem Werkzeug aus deiner XML-Schema-Datei generiert.
Java 6 integriert JAXB 2.0, und das JDK 6 Update 4 – sehr ungewöhnlich für ein Update – aktualisiert auf JAXB 2.1.
1.1.1 Bean für JAXB aufbauen
Wir wollen einen Player deklarieren, und JAXB soll ihn anschließend in ein XML-Dokument übertragen.
com/tutego/insel/xml/jaxb/Player.java, Player
@XmlRootElement
class Player
{
private String name;
private Date birthday;
public String getName()
{
return name;
}
public void setName( String name )
{
this.name = name;
}
public void setBirthday( Date birthday )
{
this.birthday = birthday;
}
public Date getBirthday()
{
return birthday;
}
}
Die Klassen-Annotation @XmlRootElement ist an der JavaBean nötig, wenn die Klasse das Wurzelelement eines XML-Baums bildet. Die Annotation stammt aus dem Paket javax.xml.bind.annotation.
1.1.2 JAXBContext und die Marshaller
Ein kleines Testprogramm baut eine Person auf bildet sie dann in XML ab – die Ausgabe der Abbildung kommt auf dem Bildschirm.
com/tutego/insel/xml/xml/jaxb/PlayerMarshaller.java, main()
Player johnPeel = new Player();
johnPeel.setName( „John Peel“ );
johnPeel.setBirthday( new GregorianCalendar(1939,Calendar.AUGUST,30).getTime() );
JAXBContext context = JAXBContext.newInstance( Player.class );
Marshaller m = context.createMarshaller();
m.setProperty( Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE );
m.marshal( johnPeel, System.out );
Nach dem Lauf kommt auf den Schirm:
<?xml version=“1.0″ encoding=“UTF-8″ standalone=“yes“?>
<player>
<birthday>1939-08-30T00:00:00+01:00</birthday>
<name>John Peel</name>
</player>
Alles bei JAXB beginnt mit der zentralen Klasse JAXBContext. Die statische Methode JAXBContext.newInstance() erwartet standardmäßig eine Aufzählung der Klassen, die JAXB behandeln soll. Der JAXBContext erzeugt den Marshaller zum Schreiben und Unmarshaller zum Lesen. Die Fabrikmethode createMarshaller() liefert einen Schreiberling, der mit marshal() das Wurzelobjekt in einen Datenstrom schreibt. Das zweite Argument von marshal() ist unter anderem ein OutputStream (wie System.out in unserem Beispiel), Writer oder File-Objekt.
JAXB beachtet standardmäßig alle Bean-Properties, also birthday und name, und nennt die XML-Elemente nach den Properties.
1.1.3 Ganze Objektgrafen schreiben und lesen
JAXB bildet nicht nur das zu schreiben Objekt ab, sondern auch rekursiv alle referenzierten Unterobjekte. Wir wollen den Spieler dazu in einen Raum setzen und den Raum in XML abbilden. Dazu muss der Raum die Annotation @XmlRootElement bekommen und bei Player kann sie entfernt werden, wenn nur der Raum selbst aber kleine Player als Wurzelobjekte zum Marshaller kommen.
com/tutego/insel/xml/xml/jaxb/Room.java, Room
@XmlRootElement( namespace = „http://tutego.com/“ )
public class Room
{
private List<Player> players = new ArrayList<Player>();
@XmlElement( name = „player“ )
public List<Player> getPlayers()
{
return players;
}
public void setPlayers( List<Player> players )
{
this.players = players;
}
}
Zwei Annotationen kommen vor: Da Room der Start des Objektgrafen ist, trägt es @XmlRootElement. Als Erweiterung ist das Element namespace für den Namensraum gesetzt, da bei eigenen XML-Dokumenten immer ein Namensraum genutzt werden soll. Weiterhin ist eine Annotation @XmlElement am Getter getPlayers() platziert, um den Namen des XML-Elements zu überschreiben, damit das XML-Element nicht <players> heißt, sondern <player>.
Kommen wir abschließend zu einem Beispiel, das einen Raum mit 2 Spielern aufbaut, und diesen Raum dann in eine XML-Datei schreibt. Statt allerdings JAXBContext direkt zu nutzen und einen Marshaller zum Schreiben und Unmarshaller zum Lesen zu erfragen, kommt im zweiten Beispiel die Utility-Klasse JAXB zum Einsatz, die ausschließlich statische überladene marshal() und unmarshal() Methoden anbietet.
Player john = new Player();
john.setName( „John Peel“ );
Player tweet = new Player();
tweet.setName( „Zwitscher Zoe“ );
Room room = new Room();
room.setPlayers( Arrays.asList( john, tweet ) );
File file = File.createTempFile( „room-jaxb-„, „.xml“ );
JAXB.marshal( room, file );
Room room2 = JAXB.unmarshal( file, Room.class );
System.out.println( room2.getPlayers().get( 0 ).getName() ); // John Peel
file.deleteOnExit();
Falls etwas beim Schreiben oder Lesen misslingt, werden die vorher geprüften Ausnahmen in einer DataBindingException ummantelt, die eine RuntimeException ist.
Die Ausgabe ist:
<?xml version=“1.0″ encoding=“UTF-8″ standalone=“yes“?>
<ns2:room xmlns:ns2=“http://tutego.com/“>
<player>
<name>John Peel</name>
</player>
<player>
<name>Zwitscher Zoe</name>
</player>
</ns2:room>
Da beim Spieler das Geburtsdatum nicht gesetzt war (null wird referenziert), wird es auch nicht in XML abgebildet.
iPhone als teures Android Handy
Guckst du hier:
Version 1.3.3 der Google App Engine
- Added two new system properties com.google.appengine.application.id and com.google.appengine.application.version
- DeadlineExceededException is now always thrown before HardDeadlineExceededError
- Decreased likelihood of "Too many URLMap" deployment errors for complex web apps
- Fixed an error where QuotaService.getCpuTimeInMegaCycles() was returning cycles instead of megacycles
- Fixed an issue between differing behavior of jsp in the production and development environments. http://code.google.com/p/googleappengine/issues/detail?id=3022
- Fixed an issue uploading webapps with .tag files. http://code.google.com/p/googleappengine/issues/detail?id=2902
Thema der Woche: Double-checked locking
Lies http://www.ibm.com/developerworks/java/library/j-dcl.html und erkläre, wo es genau bei
public static Singleton getInstance()
{
if (instance == null)
{
synchronized(Singleton.class) { //1
if (instance == null) //2
instance = new Singleton(); //3
}
}
return instance;
}
zu einem Problem bei nebenläufigen Threads kommen kann. Warum funktioniert es auch bei 2 synch. Blöcken nicht? Was hat das dem Memory-Modell zu tun?
Hinweis: Es geht nicht darum, ein Singleton korrekt zu implementieren, sondern das Java Memory Modell zu verstehen und Probleme aufzudecken, die sich aus der Nebenläufigkeit ergeben.
1.6.0_20 (6u20) Update
Kurz nach 19er Update, was einige Verbesserungen mit sich brachte, kommt das Update 20 mit nur 3 kleinen Änderungen nach. Im Wesentlichen handelt es sich um den Fix vom Bug http://www.oracle.com/technology/deploy/security/alerts/alert-cve-2010-0886.html.
Eclipse-Plugin EditBox
Ein Bild des Plugins http://editbox.sourceforge.net/ sagt alles:
Die Blöcke werden also farblich hervorgehoben.
Stelle ich mir ganz gut bei Java Anfängern vor, um sie an das Konzept von Blöcken zu gewöhnen.
GCC 4.5 ist raus, am Java (GCJ) ändert sich nix
Die neue Version von GCC 4.5 ist raus, allerdings ohne Neuerungen am GCJ. Das ist irgendwie erstaunlich, da alle auch die Compiler-Frontends Ada einige und Fortran viele Neuerungen bekommt. Naja, Objective-C ist auch nicht mit in der Liste.
Grundsätzlich profitiert natürlich GCJ von den verbesserten Internas und Unterstützung neuer Prozessoren und Optimierungen. Aber prinzipiell muss man sich schon fragen, ob GCJ überhaupt jemals mit ernstzunehmenden Enthusiasmus entwickelt wurde. Eigentlich nie.
JUnit 4 Tutorial, Java-Tests mit JUnit
Hinweis! Eine aktuelle Version des Abschnittes gibt es im Buch „Java ist auch eine Insel. Einführung, Ausbildung, Praxis“, dem 1. Inselbuch. (War für den 2. Band vorgesehen, musste wegen der Fülle des 2. Buchs kurzerhand in den 1. Band geschoben werden. Sorry für Irritationen!)
1.1 Softwaretests
Um möglichst viel Vertrauen in die eigene Codebasis zu bekommen, bieten sich Softwaretests an. Tests sind kleine Programme, die ohne Benutzerkontrolle automatisch über die Quellcodebasis laufen und anhand von Regeln zeigen, dass gewünschte Teile sich so verhalten wie gewünscht. (Die Abwesenheit von Fehlern kann eine Software natürlich nicht zeigen, aber immer zeigt ein Testfall, dass das Programm die Vorgaben aus der Spezifikation erfüllt.)
Obwohl Softwaretests extrem wichtig sind, sind sie unter Softwareentwicklern nicht unbedingt populär. Das liegt unter anderem daran, dass sie natürlich etwas Zeit kosten, die neben der tatsächlichen Entwicklung aufgewendet werden muss. Wenn dann die eigentliche Software geändert wird, müssen auch die Testfälle oftmals mit angefasst werden, so dass es gleich zwei Baustellen gibt. Und da Entwickler eigentlich immer gestern das Feature fertig stellen sollten, fallen die Testes gerne unter den Tisch. Ein weiterer Grund ist, dass einige Entwickler sich für unfehlbare Codierungsgötter halten, die jeden Programmcode (nach ein paar Stunden debuggen) für absolut korrekt, performant und wohl duftend halten.
Wie lässt sich diese skeptische Gruppe nun überzeugen, doch Tests zu schreiben? Ein großer Vorteil von automatisierten Tests ist die Eigenschaft, dass bei großen Änderungen der Quellcodebasis (Refactoring) die Testfälle automatisch sagen, ob alles korrekt verändert wurde. Denn wenn nach dem Refactoring, etwa einer Performance-Optimierung, die Tests einen Fehler melden, ist wohl etwas kaputt-optimiert worden. Da Software einer permanenten Änderung unterliegt und nie fertig ist, sollte das Argument eigentlich schon ausreichen, denn wenn eine Software eine gewisse Größe erreicht hat, ist nicht absehbar, welche Auswirklungen Änderungen an der Quellcodebasis nach sich ziehen. Dazu kommt ein weiterer Grund, sich mit Tests zu beschäftigen. Es ist der positive Nebeneffekt, dass die erzeugte Software vom Design deutlich besser ist, denn testbare Software zu schreiben ist knifflig, führt aber fast zwangsläufig zum besseren Design. Und ein besseres Design ist immer erstrebenswert, denn das erhöht die Verständlichkeit und erleichtert die spätere Anpassung der Software.
1.1.1 Vorgehen bei Schreiben von Testfällen
Die Fokussierung bei Softwaretests liegt auf zwei Attributen: automatisch und wiederholbar. Dazu ist eine Bibliothek nötig, die zwei Dinge unterstützen muss.
· Testfälle sehen immer gleich aus und bestehen aus drei Schritten. Zunächst wird ein Szenario aufgebaut, dann die zu testende Methode oder Methodenkombination aufgerufen und zum Schluss mit der spezifischen API vom Testframework geschaut, ob das ausgeführte Programm genau das gewünschte Verhalten gebracht hat. Das Übernehmen eine Art „stimmt-es-dass“-Methoden, die den gewünschten Zustand mit dem tatsächlichen Abgleichen und beim Konflikt eine Ausnahme auslösen.
· Das Testframework muss die Tests laufen lassen und im Fehlerfall eine Meldung geben; der Teil nennt sich Test-Runner.
Wir werden uns im Folgenden auf sogenannte Unit-Tests beschränken. Das sind Tests, die einzelne Bausteine (engl. units) testen. Daneben gibt es andere Tests, wie Lasttests, Performance-Tests oder Integrationstests, die aber im Folgenden keine große Rolle spielen.
Programmbibliothek für gesprochene Dauern: PrettyTime
Schwierig, einen Titel zu finden, aber wenn ich ein Beispiele gebe wird’s klar, was die LGPL-Bibliothek PrettyTime macht:
PrettyTime p = new PrettyTime(); System.out.println(p.format(new Date())); //prints: “right now”
PrettyTime t = new PrettyTime(new Date(0));
assertEquals("3 hours from now", t.format(new Date(1000 * 60 * 60 * 3)));
PrettyTime t = new PrettyTime(new Date(0));
assertEquals("3 days from now", t.format(new Date(1000 * 60 * 60 * 24 * 3)));
PrettyTime t = new PrettyTime(new Date(0));
assertEquals("3 weeks from now", t.format(new Date(1000 * 60 * 60 * 24 * 7 * 3)));
PrettyTime t = new PrettyTime(new Date(0));
assertEquals("3 months from now", t.format(new Date(2629743830L * 3L)));
PrettyTime t = new PrettyTime(new Date(0));
assertEquals("3 years from now", t.format(new Date(2629743830L * 12L * 3L)));
PrettyTime t = new PrettyTime(new Date(0));
assertEquals("12 minutes from now", t.format(new Date(1000 * 60 * 12)));
Die API kann man auch in JSF nutzen.
<h:outputText value="#{exampleBean.futureDate}">
<f:converter converterId="com.ocpsoft.PrettyTimeConverter"/>
</h:outputText>
Das ganze gibt es lokalisiert für die Sprachen
- Dutch – NL
- English – DEFAULT
- French – FR
- German – DE
- Chinese – ZH_CN
- Portugese – PT
- Spanish – ES
Voraussetzung ist Java 6.0. Der Quellcode ist aufgebläht bis zum Umfallen, aber wen das nicht stört, findet in PrettyTime eine kleine nette Bibliothek zur Zeitdarstellung.
Thema der Woche: Hessian und Burlap Protocol
- Gib eine Auflistung der bekannten Protokolle für entfernte Methodenaufrufe mit Java, etwa RMI, CORBA, SOAP, … Teile die Protokolle in die Eigenschaften plattformunabhängig und binär/textorientiert ein.
- Verschaffe einen Überblick über http://hessian.caucho.com/, http://www.caucho.com/resin-3.0/protocols/hessian-2.0-spec.xtp, http://www.caucho.com/resin-3.0/protocols/burlap.xtp, http://hessian.caucho.com/doc/hessian-java-binding-draft-spec.xtp. Was sind die Unterschiede zwischen Hessian und Burlap, wo die Stärken und Schwächen?
- Wie unterscheiden sich die Protokolle von den etablierten Protokollen? Lies dazu http://hessian.caucho.com/doc/metaprotocol-taxonomy.xtp.
- Implementierte das unter http://hessian.caucho.com/ angegeben BasicAPI-Beispiel mit Hilfe des embedded Servlet-Containers Jetty.
- Lässt sich in Spring ein RMI-Service durch einen Hessian-Service ohne großen Aufwand ersetzen?
Datentransformation mit talend
Ein Kunde einer Schulung hat mich auf ein Tool von talend aufmerksam gemacht, das ihm schnell half, Daten zu transformieren. Ich habe mir das Demo angeschaut und für eine quelloffene Software sieht das sehr gut aus:
Von der Webseite:
Talend ist der erste Anbieter einer Open Source Datenintegrationssoftware, welche durch das Open Source Modell eine Lösung für jegliche Form der Datenintegration darstellt. Dabei spielen Unternehmensgröße und Unternehmensart genauso wenig eine Rolle wie Budgetbeschränkungen oder der vorhandene technische Kenntnisstand.
Unter Datenintegration versteht man das Kombinieren und Transformieren von unterschiedlichen Daten innerhalb der gesamten IT-Infrastruktur. Typischerweise bestehen solche Prozesse aus der Extraktion von verschiedensten Datenquellen (Datenbanken, Dateien, Applikationen, Web Services, Emails, etc.), der Anwendung von diversen Transformationsregeln(Join, Lookup, Dublettenbereinigung, Berechnungen, etc.) und der endgültigen Überführung in das gewünschte Zielsystem.
Testberichte sind willkommen.
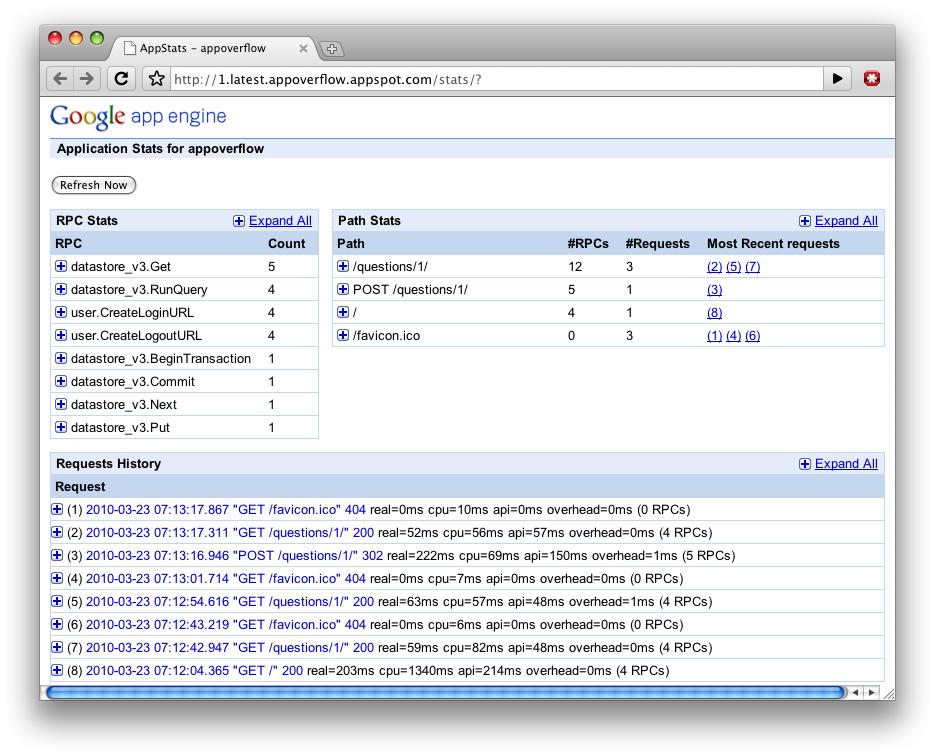
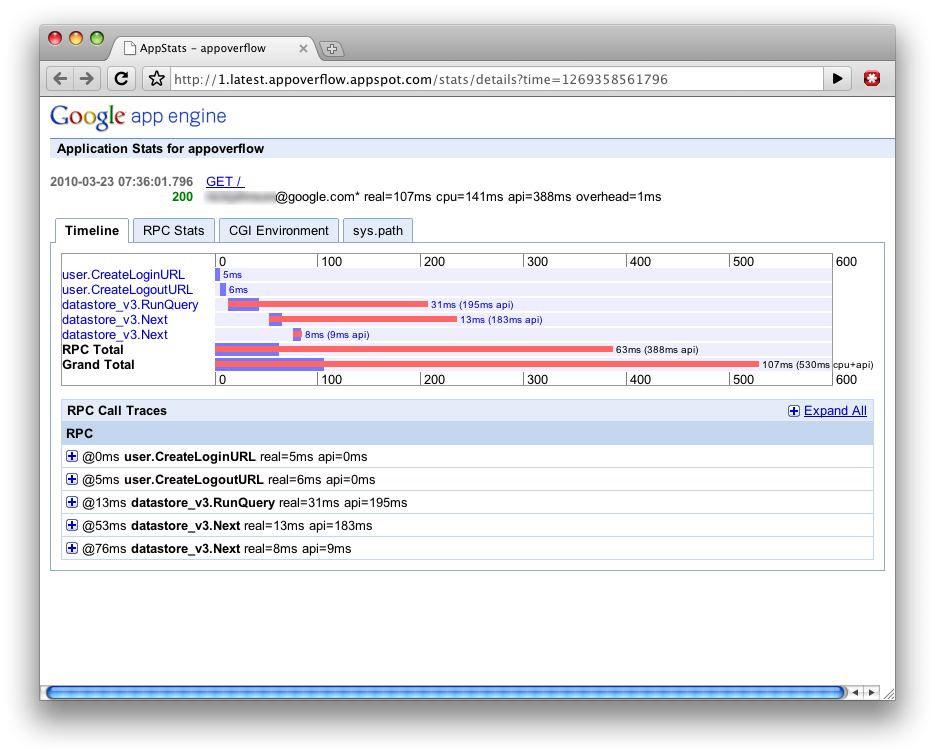
„Appstats for Java“ Profiling von Web-Requests für Google App Engine
Die Appstats for Java http://code.google.com/intl/de/appengine/docs/java/tools/appstats.html sind ein Servlet-Filter, die Zeiten für die Requests messen und alles, was mit einem Request verbunden ist. Später lässt sich das ganze auch Visualisieren. Der Blog-Eintrag http://googleappengine.blogspot.com/2010/03/easy-performance-profiling-with.html beschreibt das und liefert ein paar Screenshots mit.
Quake II auf GWT
Man glaubt es kaum und könnte es für einen 1-April-Scherz halten, aber eine Gruppe von Codern hat Quake II auf GWT portiert (http://code.google.com/p/quake2-gwt-port/). Um das möglich zu machen, mussten jedoch einige Anpassungen vorgenommen werden:
- Created a new WebGL based renderer
- Ported the network layer for multiplayer games from UDP to the WebSocket API
- Made all resource loading calls asynchronous
- Created a GWT implementation of Java nio buffers based on WebGL arrays (to be ported to ECMAScript Typed Arrays)
- Implemented a simple file system emulation for saving games and preferences using the Web Storage API
Bisher läuft das ganze nur auf Chrome.
2 GWT Bibliotheken für REST- und MVP-Anwendungen
1. http://code.google.com/p/restful-gwt/
Die History korrekt zu Implementieren ist das O und A einer GWT-Anwendung. Hier greift http://code.google.com/p/restful-gwt/ unter die Arme, in dem es wie bei REST Pfade einzelne GWT-Seiten mappt. Das Projekt steht am Anfang, die Idee ist aber nett für kleinere GWT-Anwendungen. Weiterlesen
objectify-appengine: schöne Abstraktion der Low-Level Datastore API
Die APIs JPA oder JDO sind auf einer NoSQL-Datenbank nicht optimal. Wer mit der Low-Level API programmiert, muss aber zu viel selbst machen. Das Projekt http://code.google.com/p/objectify-appengine/ ist dabei eine willkommene Vereinfachung.
Thema der Woche: NoSQL-Datenbanken
Lies ein paar Artikel auf http://nosql-database.org/links.html und erkläre die folgenden Begriffe:
- Was ist eigentlich so nicht-SQL an NoSQL?
- Welche bekannten NoSQL-Systeme gibt es? Wie unterscheiden sie sich in der Modellierung? (Etwa Key/Value, …)
- Was ist CAP?
- Was ist Map & Reduce? „Hat“ jede NoSQL-Datenbank ein Map & Reduce?
- Welche NoSQL-Datenbank wird wie angesprochen? Wie kommen Daten in und aus der Datenbank? Wie sieht eine Java-API aus?
{kind=link}
Smart GWT 2.1 ist raus
Von den Release Notes http://www.smartclient.com/smartgwt/release_notes.html#2_1:
-
GWT 2.0.3 compatible
-
New Graphite theme
-
ListGrid enhancements
- Record RollOver controls
- RollUnder Canvas support
- Background components
- Support for arbitrary widgets in cells
- Ability to display row numbers
- setMaxExpandedRecords(..) to control max. number of simultaneous expanded records
- ListGridField.setCanDragResize(), setCanReorder(), setAutoFreeze(), setShouldPrint() API’s
- Checkbox selection with grouping
- MultiColumn sort enhancements
-
TreeGrid enhancements
- Support for Checkbox tree with Cascade selection
- Support for tri-state checkboxes (selected, unselected, partial)
- Performance enhancements
-
ToolStrip enhancements
- Significant improvement in appearance
- Added ToolStripButton and ToolStripMenuButton classes
- Vertical ToolStrips
-
Print support enhancements
- ability to control which components display in print view
- print styling on a per-component basis
- support print window customizations
- API for the number of records displayed in print view (can be different from UI view)
-
Browser Plugins as widgets
- Flashlet widget
- Applet widget
- ActiveXControl widget
- SVG widget
-
Other Widget enhancements
- Window : support for footer controls
- Calendar : control dragability of events
- New IMenuButton & IPickTreeItem classes with improved appearance
- AdvancedCriteria enhancements and support for programmatic construction
- SectionStack drag reordering support
- FilterBuilder support for working with very large number of fields
- Convenience FormItem.setRequiredMessage(..) API
- TileGrids now automatically relayout if a tile resizes
- Added support for grouping for formula and summary fields
-
Performance enhancements
- Snappier TreeGrid expand / collapse
- Faster Canvas resize
- Faster Tab close (deferred destroy)
-
Logging of warnings and error to the GWT Developer Console in addition to the Smart GWT Dev. Console.
-
Improved exception handling and reporting.
-
i18n enhancements
-
Showcase enhancements and several new samples under the „New Samples“ side nav
-
27 additional enhancements and bug fixes that were logged in tracker
Buchkritik “Google Web Toolkit . GWT Java AJAX Programming. A practical guide to Google Web Toolkit for creating AJAX applications with Java”
Prabhakar Chaganti. Packt Publishing. ISBN 1847191002. 15. Februar 2007. 248 Seiten
Didaktisch ist das Buch deutlich besser aufgebaut als GWT in Action, allerdings geht es deutlich weniger in die Tiefe. Während die Autoren ein einfaches Beispiel zur Internationalisierung angeben und dann schreiben „The I18N support in GWT is quite extensive and can be used to support either simple or complicated internationalization scenarios.“ geht hier das Hanson-Tacy-Gespann deutlicher in die Tiefe. Sehr gut gefallen haben mir den praktischen Beispiele, die Ajax so bekannt gemacht hatten, etwa die Listen mit Kandidaten bei eingegebenen Suchbegriffen oder weiteres. Allerdings gibt es auch ein paar Schwachpunkte. Zunächst betrifft es die GWT-Version: das Buch basiert auf GWT RC1 von Ende 2006. So kommen Neuigkeiten aus GWT 1.4 (aktuell ist GWT 2) nicht zur Sprache. Zudem ist die Formatierung oft ungenügend. Es beginnt schon früh mit dem Satz:
When we wish to draw your attention to a particular part of a code block, the relevant lines or items will be made bold:
calendarPanel.add(calendarGrid);
calendarPanel.add(todayButton);
Und dann steht das noch nicht mal in der Einleitung in bold.
Einrückung und Formatierung sind im ganzen Buch sehr merkwürdig. Die Listings besitzen oft am Anfang eine sehr hohe Einrückung, um dann die verbleibenden Zeilen an den unmöglichsten Stellen umbrechen zu müssen. Einige Fehler sind sicherlich nur Unachtsamkeiten. Wie die folgende:
Primitive types—character, byte, short, integer, long, Boolean, float, and double
Primitive type wrapper classes—character, byte, short, integer, long, Boolean, float, and double
Oder dann zeigt ein Screenshot bei den Primzahlenbeispielen eine Zahl in Anführungszeichen, doch im Quellocode steht:
Window.alert("Yes, "+ primeNumber.getText() ...
Es fehlt hier, genauso wie bei der Fallunterscheidung beim No, das einleitende Hochkomma. Bei Konstruktoren ist ein einfaches super(); sicherlich nicht als explizite Anweisung nötig. Einige Kritikpunkte betreffen die Namensgebung. Da heißt dann eine Methode großgeschrieben ShowText() oder onEventpreview(). Stilistisch lässt sich vielleicht noch for (; rs.next();) mit einem einfachen while( rs.next() ) schreiben. Und warum sehe ich das bei so vielen Autoren Felddeklarationen der Art
private String[] items = new String[]{"apple", "peach", "orange", "banana", "plum", "avocado", ...
Wenn es auch einfach nur
private String[] items = {"apple", "peach", "orange", "banana", "plum", "avocado", ...
heißen könnte? Viele Beispiele tragen im Quellcode für die GWT-Komponenten CSS-Zuweisungen wie
searchText.setStyleName(„liveSearch-TextBox“);
Doch die CSS-Datei ist nicht angegeben! Für die Listings hätte das eigentlich auch wegfallen können—hier muss man die Beispiele von CD oder aus dem Internet nehmen. Mit den Styling ist auch eine andere Sache krumm. Statt <img border=’0′ src=’images/blank.gif’/> für eine Tabelle zu schreiben, wäre hier wohl CSS besser, also etwa <img class="border:0" src='images/blank.gif'/>. Bei den Schaltflächen müssen HTML-Zeichen nicht ausmaskiert werden: new Button("<", this); new Button(">", this); ist schlicht falsch. In der Abbildung auf Seite 41 taucht plötzlich eine Schnittstelle RemoteServiceAsync auf. Die angeblich selbst geschriebene Schnittstelle gibt es nicht, das sollte PrimesServiceAsync heißen. Beim Beispiel mit Auto Form Fill überträgt der GWT-RPC-Service eine HashMap mit den Daten. Eine interessante Alternative wäre, eine serialisierbare Bean zu deklarieren und diese zu versenden. Da kommt in den Beispielen nirgendwo vor. Platz nehmen recht viel Codeduplikate ein, da der Autor bei den Beschreibungen einen Aufbau gewählt hat, in dem erst der Quellcode als Tue-Dies-Anweisungen aufgeführt wird und später die zentralen Stellen beim Was-haben-wir-eigentlich-gemacht-Teil wiederholt. Das kostet natürlich Platz beim Druck und hätte kompakter ausfallen können. Einige Beispiele geben Beispiele für eine Ajax-Bibliotehk an, die sonst aber nicht so weit verbreitet ist. Eine Sache gibt es sogar, die im Action-Buch nicht steht – und die ich auch dort vermisste habe: wie man Dokumente lädt. Hier ist es: HTTPRequest.asyncGet("customers.csv", new ResponseTextHandler() ). Eine Auflistung der unterstützten APIs fehlt jedoch auch hier. In der Summe bleibt ein nettes gut lesbares Buch, welches schnell gelesen ist und auch nicht schwer ist.